Chapter 11. Testing and quality assurance
Table of Contents
Building real systems means caring about quality control, robustness and correctness. With the right quality assurance mechanisms in place, well-written code can feel like a precision machine, with all functions performing their tasks exactly as specified. There is no sloppiness around the edges, and the final result can be code that is self-explanatory, obviously correct -- the kind of code that inspires confidence.
In Haskell, we have several tools at our disposal for building such precise systems. The most obvious tool, and one built into the language itself, is the expressive type-system, which allows for complicated invariants to be enforced statically — making it impossible to write code violating chosen constraints. In addition, purity and polymorphism encourage a style of code that is modular, refactorable and testable. This is the kind of code that just doesn't go wrong.
Testing plays a key role in keeping code on the straight-and-narrow path. The main testing mechanisms in Haskell are traditional unit testing (via the HUnit library), and its more powerful descendant: type-based “property” testing, with QuickCheck, an open source testing framework for Haskell. Property-based testing encourages a high level approach to testing in the form of abstract invariants functions should satisfy universally, with the actual test data generated for the programmer by the testing library. In this way code can be hammered with thousands of tests that would be infeasible to write by hand, often uncovering subtle corner cases that wouldn't be found otherwise.
In this chapter we'll look at how to use QuickCheck to establish invariants in code and then re-examine the pretty printer developed in previous chapters, testing it with QuickCheck. We'll also see how to guide the testing process with GHC's code coverage tool: HPC.
QuickCheck: type-based testing
To get an overview of how property-based testing works, we'll begin with a simple scenario: you've written a specialised sorting function and want to test its behaviour.
First, we import the QuickCheck library[27], and any other modules we need:
-- file: ch11/QC-basics.hs import Test.QuickCheck import Data.List
And the function we want to test — a custom sort routine:
-- file: ch11/QC-basics.hs
qsort :: Ord a => [a] -> [a]
qsort [] = []
qsort (x:xs) = qsort lhs ++ [x] ++ qsort rhs
where lhs = filter (< x) xs
rhs = filter (>= x) xsThis is the classic Haskell sort implementation: a study in functional programming elegance, if not efficiency (this isn't an inplace sort). Now, we'd like to check that this function obeys the basic rules a good sort should follow. One useful invariant to start with, and one that comes up in a lot of purely functional code, is idempotency — applying a function twice has the same result as applying it only once. For our sort routine, a stable sort algorithm, this should certainly be true, or things have gone horribly wrong! This invariant can be encoded as a property simply:
-- file: ch11/QC-basics.hs prop_idempotent xs = qsort (qsort xs) == qsort xs
We'll use the QuickCheck convention of prefixing test properties with
prop_ to distinguish them from normal code. This idempotency
property is written simply as a Haskell function stating an equality that
must hold for any input data that is sorted. We can check this makes sense
for a few simple cases by hand:
ghci>prop_idempotent []Trueghci>prop_idempotent [1,1,1,1]Trueghci>prop_idempotent [1..100]Trueghci>prop_idempotent [1,5,2,1,2,0,9]True
Looking good. However, writing out the input data by hand is tedious, and violates the moral code of the efficient functional programmer: let the machine do the work! To automate this the QuickCheck library comes with a set of data generators for all the basic Haskell data types. QuickCheck uses the Arbitrary typeclass to present a uniform interface to (pseudo-)random data generation with the type system used to resolve which generator to use. QuickCheck normally hides the data generation plumbing, however we can also run the generators by hand to get a sense for the distribution of data QuickCheck produces. For example, to generate a random list of boolean values:
ghci>generate 10 (System.Random.mkStdGen 2) arbitrary :: [Bool][False,False,False,False,False,True]
QuickCheck generates test data like this and passes it to the property of our
choosing, via the quickCheck function. The type of the property
itself determines which data generator is used. quickCheck then
checks that for all the test data produced, the property is satisfied.
Now, since our idempotency test is polymorphic in the list element type, we
need to pick a particular type to generate test data for, which we write as a
type constraint on the property. To run the test, we just call
quickCheck with our property function, set to the required data
type (otherwise the list element type will default to the uninteresting
() type):
ghci>:type quickCheckquickCheck :: (Testable a) => a -> IO ()ghci>quickCheck (prop_idempotent :: [Integer] -> Bool)00, passed 100 tests.
For the 100 different lists generated, our property held — great!
When developing tests, it is often useful to see the actual data
generated for each test. To do this, we would replace
quickCheck with its sibling, verboseCheck, to see
(verbose) output for each test. Now, let's look at more sophisticated
properties that our function might satisfy.
Testing for properties
Good libraries consist of a set of orthogonal primitives having sensible relationships to each other. We can use QuickCheck to specify the relationships between functions in our code, helping us find a good library interface by developing functions that are interrelated via useful properties. QuickCheck in this way acts as an API "lint" tool — it provides machine support for ensuring our library API makes sense.
The list sorting function should certainly have a number of interesting
properties that tie it to other list operations. For example: the first
element in a sorted list should always be the smallest element of the input list.
We might be tempted to specify this intuition in Haskell, using the
List library's minimum function:
-- file: ch11/QC-basics.hs prop_minimum xs = head (qsort xs) == minimum xs
Testing this, though, reveals an error:
ghci>quickCheck (prop_minimum :: [Integer] -> Bool)0** Exception: Prelude.head: empty list
The property failed when sorting an empty list — for which
head and minimum are't defined, as we can see from
their definition:
-- file: ch11/minimum.hs head :: [a] -> a head (x:_) = x head [] = error "Prelude.head: empty list" minimum :: (Ord a) => [a] -> a minimum [] = error "Prelude.minimum: empty list" minimum xs = foldl1 min xs
So this property will only hold for non-empty lists. QuickCheck, thankfully,
comes with a full property writing embedded language, so we can specify more
precisely our invariants, filtering out values we don't want to consider.
For the empty list case, we really want to say: if the
list is non-empty, then the
first element of the sorted result is the minimum. This is done by using the
(==>) implication function, which filters out invalid data
before running the property:
-- file: ch11/QC-basics.hs prop_minimum' xs = not (null xs) ==> head (qsort xs) == minimum xs
The result is quite clean. By separating out the empty list case, we can now confirm the property does in fact hold:
ghci>quickCheck (prop_minimum' :: [Integer] -> Property)00, passed 100 tests.
Note that we had to change the type of the property from being a simple Bool result to the more general Property type (the property itself is now a function that filters non-empty lists, before testing them, rather than a simple boolean constant).
We can now complete the basic property set for the sort function with some
other invariants that it should satisfy: that the output is ordered (each
element should be smaller than, or equal to, its successor); that the output
is a permutation of the input (which we achieve via the list difference
function, (\\)); that the last sorted element should be the
largest element; and if we find the smallest element of two different lists,
that should be the first element if we append and sort those lists. These
properties can be stated as:
-- file: ch11/QC-basics.hs
prop_ordered xs = ordered (qsort xs)
where ordered [] = True
ordered [x] = True
ordered (x:y:xs) = x <= y && ordered (y:xs)
prop_permutation xs = permutation xs (qsort xs)
where permutation xs ys = null (xs \\ ys) && null (ys \\ xs)
prop_maximum xs =
not (null xs) ==>
last (qsort xs) == maximum xs
prop_append xs ys =
not (null xs) ==>
not (null ys) ==>
head (qsort (xs ++ ys)) == min (minimum xs) (minimum ys)Testing against a model
Another technique for gaining confidence in some code is to test it against a model implementation. We can tie our implementation of list sort to the reference sort function in the standard list library, and, if they behave the same, we gain confidence that our sort does the right thing.
-- file: ch11/QC-basics.hs prop_sort_model xs = sort xs == qsort xs
This kind of model-based testing is extremely powerful. Often developers will have a reference implementation or prototype that, while inefficient, is correct. This can then be kept around and used to ensure optimised production code conforms to the reference. By building a large suite of these model-based tests, and running them regularly (on every commit, for example), we can cheaply ensure the precision of our code. Large Haskell projects often come bundled with property suites comparable in size to the project itself, with thousands of invariants tested on every change, keeping the code tied to the specification, and ensuring it behaves as required.
Testing case study: specifying a pretty printer
Testing individual functions for their natural properties is one of the basic building blocks that guides development of large systems in Haskell. We'll look now at a more complicated scenario: taking the pretty printing library developed in earlier chapters, and building a test suite for it.
Generating test data
Recall that the pretty printer is built around the Doc, an algebraic data type that represents well-formed documents:
-- file: ch11/Prettify2.hs
data Doc = Empty
| Char Char
| Text String
| Line
| Concat Doc Doc
| Union Doc Doc
deriving (Show,Eq)The library itself is implemented as a set of functions that build and transform values of this document type, before finally rendering the finished document to a string.
QuickCheck encourages an approach to testing where the developer
specifies invariants that should hold for any data we can throw at the
code. To test the pretty printing library, then, we'll need a source of
input data. To do this, we take advantage of the small combinator suite for building
random data that QuickCheck provides via the
Arbitrary class. The class provides a function,
arbitrary, to generate data of each type, and with this we
can define our data generator for our custom data types.
[28]
-- file: ch11/Arbitrary.hs class Arbitrary a where arbitrary :: Gen a
One thing to notice is that the generators run in a Gen
environment, indicated by the type. This is a simple state-passing monad
that is used to hide the random number generator state that is threaded
through the code. We'll look thoroughly at monads in later chapters, but
for now it suffices to know that, as Gen is defined as a
monad, we can use do syntax to write new generators that
access the implicit random number source. To actually write generators
for our custom type we use any of a set of functions defined in the
library for introducing new random values and gluing them together to
build up data structures of the type we're interested in. The types of
the key functions are:
-- file: ch11/Arbitrary.hs elements :: [a] -> Gen a choose :: Random a => (a, a) -> Gen a oneof :: [Gen a] -> Gen a
The function elements, for example, takes a list of values,
and returns a generator of random values from that list.
choose and oneof we'll use later. With this,
we can start writing generators for simple data types. For example, if
we define a new data type for ternary logic:
-- file: ch11/Arbitrary.hs
data Ternary
= Yes
| No
| Unknown
deriving (Eq,Show)we can write an Arbitrary instance for the Ternary type by defining a function that picks elements from a list of the possible values of Ternary type:
-- file: ch11/Arbitrary.hs instance Arbitrary Ternary where arbitrary = elements [Yes, No, Unknown]
Another approach to data generation is to generate values for one
of the basic Haskell types and then translate those values into the
type you're actually interested in. We could have written the
Ternary instance by generating integer values
from 0 to 2 instead, using choose, and then mapping
them onto the ternary values:
-- file: ch11/Arbitrary2.hs
instance Arbitrary Ternary where
arbitrary = do
n <- choose (0, 2) :: Gen Int
return $ case n of
0 -> Yes
1 -> No
_ -> UnknownFor simple sum types, this approach works nicely, as the integers map nicely onto the constructors of the data type. For product types (such as structures and tuples), we need to instead generate each component of the product separately (and recursively for nested types), and then combine the components. For example, to generate random pairs of random values:
-- file: ch11/Arbitrary.hs
instance (Arbitrary a, Arbitrary b) => Arbitrary (a, b) where
arbitrary = do
x <- arbitrary
y <- arbitrary
return (x, y)So let's now write a generator for all the different variants of the Doc type. We'll start by breaking the problem down, first generating random constructors for each type, then, depending on the result, the components of each field. The most complicated case are the union and concatenation variants.
First, though, we need to write an instance for generating random characters — QuickCheck doesn't have a default instance for characters, due to the abundance of different text encodings we might want to use for character tests. We'll write our own, and, as we don't care about the actual text content of the document, a simple generator of alphabetic characters and punctuation will suffice (richer generators are simple extensions of this basic approach):
-- file: ch11/QC.hs
instance Arbitrary Char where
arbitrary = elements (['A'..'Z'] ++ ['a' .. 'z'] ++ " ~!@#$%^&*()")
With this in place, we can now write an instance for documents, by
enumerating the constructors, and filling the fields in. We choose a
random integer to represent which document variant to generate, and
then dispatch based on the result. To generate concat or union document
nodes, we just recurse on arbitrary, letting type
inference determine which instance of Arbitrary we mean:
-- file: ch11/QC.hs
instance Arbitrary Doc where
arbitrary = do
n <- choose (1,6) :: Gen Int
case n of
1 -> return Empty
2 -> do x <- arbitrary
return (Char x)
3 -> do x <- arbitrary
return (Text x)
4 -> return Line
5 -> do x <- arbitrary
y <- arbitrary
return (Concat x y)
6 -> do x <- arbitrary
y <- arbitrary
return (Union x y)
That was fairly straightforward, and we can clean it up some more by
using the oneof function, whose type we saw earlier, to
pick between different generators in a list (we can also use the
monadic combinator, liftM to avoid naming intermediate
results from each generator):
-- file: ch11/QC.hs
instance Arbitrary Doc where
arbitrary =
oneof [ return Empty
, liftM Char arbitrary
, liftM Text arbitrary
, return Line
, liftM2 Concat arbitrary arbitrary
, liftM2 Union arbitrary arbitrary ]The latter is more concise, just picking between a list of generators, but they describe the same data either way. We can check that the output makes sense, by generating a list of random documents (seeding the pseudo-random generator with an initial seed of 2):
ghci>generate 10 (System.Random.mkStdGen 2) arbitrary :: [Doc][Line,Empty,Union Empty Line,Union (Char 'R') (Concat (Union Line (Concat (Text "i@BmSu") (Char ')'))) (Union (Concat (Concat (Concat (Text "kqV!iN") Line) Line) Line) Line)),Char 'M',Text "YdwVLrQOQh"]
Looking at the output we see a good mix of simple, base cases, and some more complicated nested documents. We'll be generating hundreds of these each test run, so that should do a pretty good job. We can now write some generic properties for our document functions.
Testing document construction
Two of the basic functions on documents are the null document constant
(a nullary function), empty, and the append function. Their types are:
-- file: ch11/Prettify2.hs empty :: Doc (<>) :: Doc -> Doc -> Doc
Together, these should have a nice property: appending or prepending the empty list onto a second list, should leave the second list unchanged. We can state this invariant as a property:
-- file: ch11/QC.hs
prop_empty_id x =
empty <> x == x
&&
x <> empty == xConfirming that this is indeed true, we're now underway with our testing:
ghci>quickCheck prop_empty_id00, passed 100 tests.
To look at what actual test documents were generated (by replacing
quickCheck with verboseCheck). A good
mixture of both simple and complicated cases are being generated.
We can refine the data generation further, with constraints on the
proportion of generated data, if desirable.
Other functions in the API are also simple enough to have their behaviour fully described via properties. By doing so we can maintain an external, checkable description of the function's behaviour, so later changes won't break these basic invariants.
-- file: ch11/QC.hs prop_char c = char c == Char c prop_text s = text s == if null s then Empty else Text s prop_line = line == Line prop_double d = double d == text (show d)
These properties are enough to fully test the structure returned by the basic document operators. To test the rest of the library will require more work.
Using lists as a model
Higher order functions are the basic glue of reusable programming, and
our pretty printer library is no exception — a custom fold
function is used internally to implement both document concatenation
and interleaving separators between document chunks. The
fold defined for documents takes a list of document
pieces, and glues them all together with a supplied combining function:
-- file: ch11/Prettify2.hs fold :: (Doc -> Doc -> Doc) -> [Doc] -> Doc fold f = foldr f empty
We can write tests in isolation for specific instances of fold easily. Horizontal concatenation of documents, for example, is easy to specify by writing a reference implementation on lists:
-- file: ch11/QC.hs
prop_hcat xs = hcat xs == glue xs
where
glue [] = empty
glue (d:ds) = d <> glue ds
It is a similar story for punctuate, where we can model
inserting punctuation with list interspersion (from
Data.List, intersperse is a function that
takes an element and interleaves it between other elements of a list):
-- file: ch11/QC.hs prop_punctuate s xs = punctuate s xs == intersperse s xs
While this looks fine, running it reveals a flaw in our reasoning:
ghci>quickCheck prop_punctuateFalsifiable, after 6 tests: Empty [Line,Text "",Line]
The pretty printing library optimises away redundant empty documents,
something the model implementation doesn't, so we'll need to augment our
model to match reality. First, we can intersperse the punctuation text
throughout the document list, then a little loop to clean up the
Empty documents scattered through, like so:
-- file: ch11/QC.hs
prop_punctuate' s xs = punctuate s xs == combine (intersperse s xs)
where
combine [] = []
combine [x] = [x]
combine (x:Empty:ys) = x : combine ys
combine (Empty:y:ys) = y : combine ys
combine (x:y:ys) = x `Concat` y : combine ysRunning this in GHCi, we can confirm the result. It is reassuring to have the test framework spot the flaws in our reasoning about the code — exactly what we're looking for:
ghci>quickCheck prop_punctuate'00, passed 100 tests.
Putting it altogether
We can put all these tests together in a single file, and run them simply by using one of QuickCheck's driver functions. Several exist, including elaborate parallel ones. The basic batch driver is often good enough, however. All we need do is set up some default test parameters, and then list the functions we want to test:
-- file: ch11/Run.hs
import Prettify2
import Test.QuickCheck.Batch
options = TestOptions
{ no_of_tests = 200
, length_of_tests = 1
, debug_tests = False }
main = do
runTests "simple" options
[ run prop_empty_id
, run prop_char
, run prop_text
, run prop_line
, run prop_double
]
runTests "complex" options
[ run prop_hcat
, run prop_puncutate'
]We've structured the code here as a separate, standalone test script, with instances and properties in their own file, separate to the library source. This is typical for library projects, where the tests are kept apart from the library itself, and import the library via the module system. The test script can then be compiled and executed:
$ghc --make Run.hs$./Runsimple : ..... (1000) complex : .. (400)
A total of 1400 individual tests were created, which is comforting. We can increase the depth easily enough, but to find out exactly how well the code is being tested we should turn to the built in code coverage tool, HPC, which can state precisely what is going on.
Measuring test coverage with HPC
HPC (Haskell Program Coverage) is an extension to the compiler to observe what parts of the code were actually executed during a given program run. This is useful in the context of testing, as it lets us observe precisely which functions, branches and expressions were evaluated. The result is precise knowledge about the percent of code tested, that's easy to obtain. HPC comes with a simple utility to generate useful graphs of program coverage, making it easy to zoom in on weak spots in the test suite.
To obtain test coverage data, all we need to do is add the
-fhpc flag to the command line, when compiling the tests:
$ ghc -fhpc Run.hs --make
$ ./Run
simple : ..... (1000)
complex : .. (400)
During the test run the trace of the program is written to .tix and .mix
files in the current directory. Afterwards, these files are used by the
command line tool, hpc, to display various statistics about
what happened. The basic interface is textual.
To begin, we can get a summary of the code tested during the run using
the report flag to hpc. We'll exclude the test
programs themselves, (using the --exclude flag), so as to
concentrate only on code in the pretty printer library.
Entering the following into the console:
$ hpc report Run --exclude=Main --exclude=QC
18% expressions used (30/158)
0% boolean coverage (0/3)
0% guards (0/3), 3 unevaluated
100% 'if' conditions (0/0)
100% qualifiers (0/0)
23% alternatives used (8/34)
0% local declarations used (0/4)
42% top-level declarations used (9/21)
we see that, on the last line, 42% of top level definitions were
evaluated during the test run. Not too bad for a first attempt.
As we test more and more functions from the library, this figure will
rise. The textual version is useful for a quick summary, but to really
see what's going on it is best to look at the marked up output.
To generate this, use the markup flag instead:
$ hpc markup Run --exclude=Main --exclude=QC
This will generate one html file for each Haskell source file, and some
index files. Loading the file hpc_index.html into a
browser, we can see some pretty graphs of the code coverage:

Not too bad. Clicking through to the pretty module itself, we see the actual source of the program, marked up in bold yellow for code that wasn't tested, and code that was executed simply bold.
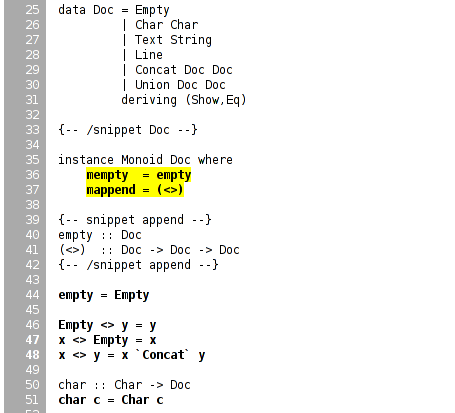
We forgot to test the Monoid instance, for example, and some of the more complicated functions. HPC helps keep our test suite honest. Let's add a test for the typeclass instance of Monoid, the class of types that support appending and empty elements:
-- file: ch11/QC.hs
prop_mempty_id x =
mempty `mappend` x == x
&&
x `mappend` mempty == (x :: Doc)Running this property in ghci, to check it is correct:
ghci>quickCheck prop_mempty_id00, passed 100 tests.
We can now recompile and run the test driver. It is important to remove the old .tix file first though, or an error will occur as HPC tries to combine the statistics from separate runs:
$ ghc -fhpc Run.hs --make -no-recomp
$ ./Run
Hpc failure: inconsistent number of tick boxes
(perhaps remove Run.tix file?)
$ rm *.tix
$ ./Run
simple : ..... (1000)
complex : ... (600)
Another two hundred tests were added to the suite, and our coverage statistics improves to 52 percent of the code base:

HPC ensures that we're honest in our testing, as anything less than 100% coverage will be pointed out in glaring color. In particular, it ensures the programmer has to think about error cases, and complicated branches with obscure conditions, all forms of code smell. When combined with a saturating test generation system, like QuickCheck's, testing becomes a rewarding activity, and a core part of Haskell development.
[27] Throughout this chapter we'll use QuickCheck 1.0 (classic QuickCheck). It should be kept in mind that a some functions may differ in later releases of the library.
[28]
The class also defines a method, coarbitrary,
which given a value of some type, yields a function for new generators.
We can disregard for now, as it is only needed for generating random
values of function type. One result of disregarding
coarbitrary is that GHC will warn about it not being
defined, however, it is safe to ignore these warnings.
 Want to stay up to date? Subscribe to the comment feed for
Want to stay up to date? Subscribe to the comment feed for