![]()
This is the followup to my talk LLVM Optimized Python at the Harvard-Smithsonian Center for Astrophysics, we'll do the deep dive that I didn't have time for. We're going to build a single module Numba-like compiler for Python. It won't be nearly as featureful or complete, but should demonstrate how you can go about building your own little LLVM specializer for a subset of Python or your own custom DSL expression compiler; and integrating it with the standard NumPy/SciPy stack for whatever scientific computing domain you work. The full source for this project is available on Github and comes in at 1000 lines for the whole specializer, very tiny!
There's a whole slew of interesting domains where this kind of on-the-fly specializing compiler can be used:
- Computation kernels for MapReduce
- Financial backtesting
- Dense linear algebra
- Image processing
- Data pipeline hotspots
- Speeding up SQL queries in PostgreSQL
- Molecular dynamics
- Compiling UDFs for Cloudera Impala
Python is great for rapid development and high-level thinking, but is slow due to too many level of indirection, hashmap lookups, broken parallelism,slow garbage collector, and boxed PyObject types. With LLVM we can keep writing high-level code and not sacrafice performance.
You will need python, llvm, llvmpy, numpy and a bit of time. The best way to get all of these is to install Anaconda maintained by my good friend Ilan. Don't add any more entropy to the universe by compiling NumPy from source, just use Anaconda.
import llvm.ee as le
import llvm.core as lc
int_type = lc.Type.int()
float_type = lc.Type.double()
void_type = lc.Type.void()
def func(name, module, rettype, argtypes):
func_type = lc.Type.function(rettype, argtypes, False)
lfunc = lc.Function.new(module, func_type, name)
entry_block = lfunc.append_basic_block("entry")
builder = lc.Builder.new(entry_block)
return (lfunc, builder)
We'll create the toplevel LLVM module which will hold all of our definitions. When we call Python's __repr__ function it will print out the LLVM IR to the module.
mod = lc.Module.new('mymodule')
print(mod)
We now create the builder function which we'll use to populate the basic block structure of the module. Again, when we call Python's repr it will print out the LLVM IR for the function definition this time.
(fn, builder) = func('main', mod, int_type, [])
print(fn)
And we just create a constant integer and use the builder to emit a ret instruction to return the current entry basic block and yield the constant value.
value = lc.Constant.int(int_type, 42)
block = builder.ret(value)
print(mod)
print(mod.to_native_assembly())
So that's pretty swell, we have a way to interactively generate machine code at runtime in Python! Now we'll use the LLVM JIT to actually actually execute the code and interchange values between the CPython runtime and the LLVM JIT.
tm = le.TargetMachine.new(features='', cm=le.CM_JITDEFAULT)
eb = le.EngineBuilder.new(mod)
jit = eb.create(tm)
ret = jit.run_function(fn, [])
print(ret.as_int())
That's pretty cool! We've just created machine code on the fly and executed it inside of LLVM JIT inside CPython yielding value that we can work with in regular python. If the wheels aren't spinning in your head about what you can do with this awesome power, then they should be!
So now let's set about building a tiny pipeline to support a custom autojit decorator. At the end we should be able to specialize the following dot product into efficient machine code.
@autojit
def dot(a, b):
c = 0
n = a.shape[0]
for i in range(n):
c += a[i]*b[i]
return c
LLVM Primer

LLVM is the engine that drives our effort. It is a modern compiler framework and intermediate representation language together with toolchain for manipulating and optimizing this language.
Basic Types
LLVM types are your typical machine types plus pointers, structs, vectors and arrays.
i1 1 ; boolean bit
i32 299792458 ; integer
float 7.29735257e-3 ; single precision
double 6.62606957e-34 ; double precision{float, i64} ; structure
{float, {double, i3}} ; nested structure
<{float, [2 x i3]}> ; packed structure[10 x float] ; Array of 10 floats
[10 x [20 x i32]] ; Array of 10 arrays of 20 integers.<8 x float> ; Vector of width 8 of floatsfloat* ; Pointer to a float
[25 x float]* ; Pointer to an arrayInstructions
All instructions are assignment to a unique virtual register. In SSA (Single Static Assignment) a register is never assigned to more than once.
%result = add i32 10, 20Symbols used in an LLVM module are either global or local. Global symbols begin with @ and local symbols begin with %.
The numerical instructions are:
add: Integer additionfadd: Floating point additionsub: Integer subtractionfsub: Floating point subtractionmul: Integer multiplicationfmul: Floating point multiplicationudiv: Unsigned integer quotientsdiv: Signed integer quotientfdiv: Floating point quotienturem: Unsigned integer remaindersrem: Signed integer remainderfrem: Floating point integer remainder
Memory
LLVM uses the traditional load/store model:
load: Load a typed value from a given referencestore: Store a typed value in a given referencealloca: Allocate a pointer to memory on the virtual stack
%ptr = alloca i32
store i32 3, i32* %ptr
%val = load i32* %ptrFunctions
Functions are defined by as a collection of basic blocks, a return type and argument types. Function names must be unique in the module.
define i32 @add(i32 %a, i32 %b) {
%1 = add i32 %a, %b
ret i32 %1
}Basic Blocks
The function is split across basic blocks which hold sequences of instructions and a terminator instruction which either returns or jumps to another local basic block.
define i1 @foo() {
entry:
br label %next
next:
br label %return
return:
ret i1 0
}Return
A function must have a terminator, one of such instructions is a ret which returns a value to the stack.
define i1 @foo() {
ret i1 0
}
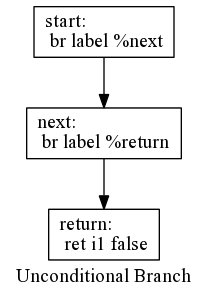
Unconditional Branch
An unconditional branch jumps unconditionally to a labeled basic block.
define i1 @foo() {
start:
br label %next
next:
br label %return
return:
ret i1 0
}
Conditional Branch
define i32 @foo() {
start:
br i1 true, label %left, label %right
left:
ret i32 10
right:
ret i32 20
}
Phi
Phi nodes yield a value that depends on the operand corresponding to their predecessor basic block. These are used for implementing loops in SSA.
define i32 @foo() {
start:
br i1 true, label %left, label %right
left:
%plusOne = add i32 0, 1
br label %merge
right:
br label %merge
merge:
%join = phi i32 [ %plusOne, %left], [ -1, %right]
ret i32 %join
}
Switch
Switch statements are like switch statements in C, and can be used to build jump tables.
define i32 @foo(i32 %a) {
entry:
switch i32 %a, label %default [ i32 0, label %f
i32 1, label %g
i32 2, label %h ]
f:
ret i32 1
g:
ret i32 2
h:
ret i32 3
default:
ret i32 0
}
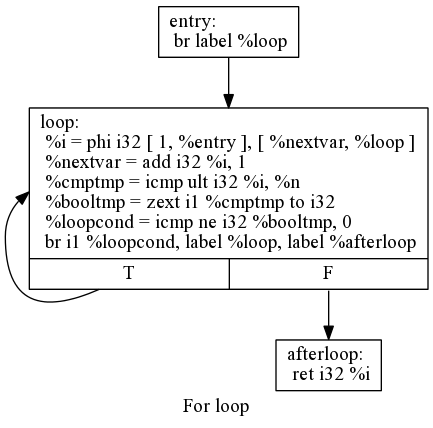
Loops
Loops are written in terms of conditional branches and phi nodes.
For example the translation of the following C code:
int count(int n)
{
int i = 0;
while(i < n)
{
i++;
}
return i;
}Into LLVM:
define i32 @count(i32 %n) {
entry:
br label %loop
loop:
%i = phi i32 [ 1, %entry ], [ %nextvar, %loop ]
%nextvar = add i32 %i, 1
%cmptmp = icmp ult i32 %i, %n
%booltmp = zext i1 %cmptmp to i32
%loopcond = icmp ne i32 %booltmp, 0
br i1 %loopcond, label %loop, label %afterloop
afterloop:
ret i32 %i
}
Toolchain
The command line utilities for LLVM can be used to transform IR to and from various forms and run optimizations over it. Everything we can do from the C++ API or llvmpy can also be done from the command line.
$ llc example.ll -o example.s # compile
$ lli example.ll # execute
$ opt -S example.bc -o example.ll # to assembly
$ opt example.ll -o example.bc # to bitcode
$ opt -O3 example.ll -o example.opt.ll -S # run optimizer
$ opt -view-cfg module.ll # view control flow graphAnd that's basically all you need to know about LLVM. Also get used to segfaulting the Python interpreter a lot when using llvmpy.
Python AST
Python's internal AST is accessible from within the Python interpreter. Really the only time you'd ever use this module is if you're doing crazy metaprogramming, which is what we're about to do! Ostensibly we're going to be taking an arbitrary function introspecting it's AST and then mapping it into another syntax called the Core which we'll endow with a different (C-like) semantics on top of as well as doing type inference on the logic to make the AST explicitly typed.
- https://greentreesnakes.readthedocs.org
- https://docs.python.org/2/library/ast.html
Hat tip to John Riehl for this pretty printing technique.
import ast
import pprint
def ast2tree(node, include_attrs=True):
def _transform(node):
if isinstance(node, ast.AST):
fields = ((a, _transform(b))
for a, b in ast.iter_fields(node))
if include_attrs:
attrs = ((a, _transform(getattr(node, a)))
for a in node._attributes
if hasattr(node, a))
return (node.__class__.__name__, dict(fields), dict(attrs))
return (node.__class__.__name__, dict(fields))
elif isinstance(node, list):
return [_transform(x) for x in node]
elif isinstance(node, str):
return repr(node)
return node
if not isinstance(node, ast.AST):
raise TypeError('expected AST, got %r' % node.__class__.__name__)
return _transform(node)
def pformat_ast(node, include_attrs=False, **kws):
return pprint.pformat(ast2tree(node, include_attrs), **kws)
So if we feed this function a source string, the ast module will go off an pares it into the AST and we'll get this nicely presented nested-dict for it's field structure. In fact we'll use the ast.Node for our custom AST just so that we can reuse this pretty printer.
source = """
def f(x):
return f(x+1)
"""
print(pformat_ast(ast.parse(source)))
Core Language
First we'll need to bring in a few libraries, pretty standard fare standard library stuff. And a few LLVM libraries, more on this later.
from __future__ import print_function
import sys
import ast
import types
import ctypes
import inspect
import pprint
import string
import numpy as np
from itertools import tee, izip
from textwrap import dedent
from collections import deque, defaultdict
import llvm.core as lc
import llvm.passes as lp
import llvm.ee as le
from llvm.core import Module, Builder, Function, Type, Constant
DEBUG = False
Our Core language will be a simple expression language with 12 terms that we will condense a subset of the much larger Python AST into.
e : var (Variable)
| n = e (Assignment)
| return e (Return)
| loop n e e [e] (Loop Construct)
| %int (Integer)
| %float (Float)
| %bool (Boolean)
| e {e} (Variadic Application)
| function n {e} [e] (Variadic Function)
| prim n (Primop)
| index e e (Array indexing)
| noop (Noop)Our core language will have two forms, one is untyped and the other has all named expressions (n) annotated with an attached type field.
class Var(ast.AST):
_fields = ["id", "type"]
def __init__(self, id, type=None):
self.id = id
self.type = type
class Assign(ast.AST):
_fields = ["ref", "val", "type"]
def __init__(self, ref, val, type=None):
self.ref = ref
self.val = val
self.type = type
class Return(ast.AST):
_fields = ["val"]
def __init__(self, val):
self.val = val
class Loop(ast.AST):
_fields = ["var", "begin", "end", "body"]
def __init__(self, var, begin, end, body):
self.var = var
self.begin = begin
self.end = end
self.body = body
class App(ast.AST):
_fields = ["fn", "args"]
def __init__(self, fn, args):
self.fn = fn
self.args = args
class Fun(ast.AST):
_fields = ["fname", "args", "body"]
def __init__(self, fname, args, body):
self.fname = fname
self.args = args
self.body = body
class LitInt(ast.AST):
_fields = ["n"]
def __init__(self, n, type=None):
self.n = n
self.type = type
class LitFloat(ast.AST):
_fields = ["n"]
def __init__(self, n, type=None):
self.n = n
self.type = None
class LitBool(ast.AST):
_fields = ["n"]
def __init__(self, n):
self.n = n
class Prim(ast.AST):
_fields = ["fn", "args"]
def __init__(self, fn, args):
self.fn = fn
self.args = args
class Index(ast.AST):
_fields = ["val", "ix"]
def __init__(self, val, ix):
self.val = val
self.ix = ix
class Noop(ast.AST):
_fields = []
In similar fashion we have a very simple type system. Our function type is variadic, it takes a tuple of arguments to a single output.
t : a (Type Variable)
| C {t} (Named Constructor)
| t (Type Application)
| [t] -> t (Function type)The basic constructors will simply be the machine types. By default we will map Python's integer to int64 and floating point to double. Python's integer type is an arbitrary precision integer, whereas LLVM is a machine integer so obviously there are different semantics.
class TVar(object):
def __init__(self, s):
self.s = s
def __hash__(self):
return hash(self.s)
def __eq__(self, other):
if isinstance(other, TVar):
return (self.s == other.s)
else:
return False
def __str__(self):
return self.s
__repr__ = __str__
class TCon(object):
def __init__(self, s):
self.s = s
def __eq__(self, other):
if isinstance(other, TCon):
return (self.s == other.s)
else:
return False
def __hash__(self):
return hash(self.s)
def __str__(self):
return self.s
__repr__ = __str__
class TApp(object):
def __init__(self, a, b):
self.a = a
self.b = b
def __eq__(self, other):
if isinstance(other, TApp):
return (self.a == other.a) & (self.b == other.b)
else:
return False
def __hash__(self):
return hash((self.a, self.b))
def __str__(self):
return str(self.a) + " " + str(self.b)
__repr__ = __str__
class TFun(object):
def __init__(self, argtys, retty):
assert isinstance(argtys, list)
self.argtys = argtys
self.retty = retty
def __eq__(self, other):
if isinstance(other, TFun):
return (self.argtys == other.argtys) & (self.retty == other.retty)
else:
return False
def __str__(self):
return str(self.argtys) + " -> " + str(self.retty)
__repr__ = __str__
def ftv(x):
if isinstance(x, TCon):
return set()
elif isinstance(x, TApp):
return ftv(x.a) | ftv(x.b)
elif isinstance(x, TFun):
return reduce(set.union, map(ftv, x.argtys)) | ftv(x.retty)
elif isinstance(x, TVar):
return set([x])
def is_array(ty):
return isinstance(ty, TApp) and ty.a == TCon("Array")
int32 = TCon("Int32")
int64 = TCon("Int64")
float32 = TCon("Float")
double64 = TCon("Double")
void = TCon("Void")
array = lambda t: TApp(TCon("Array"), t)
array_int32 = array(int32)
array_int64 = array(int64)
array_double64 = array(double64)
The Python to Core translator is a fairly unremarkable NodeVisitor class. It recursively descends through the Python AST compressing it into our Core form. For our example application this is obviously only a very small subset of the entire AST, and a lot of cases are missing. We are going to support basic loops, arithmetic with addition and multiplication, numeric literals, and array indexing.
class PythonVisitor(ast.NodeVisitor):
def __init__(self):
pass
def __call__(self, source):
if isinstance(source, types.ModuleType):
source = dedent(inspect.getsource(source))
if isinstance(source, types.FunctionType):
source = dedent(inspect.getsource(source))
if isinstance(source, types.LambdaType):
source = dedent(inspect.getsource(source))
elif isinstance(source, (str, unicode)):
source = dedent(source)
else:
raise NotImplementedError
self._source = source
self._ast = ast.parse(source)
return self.visit(self._ast)
def visit_Module(self, node):
body = map(self.visit, node.body)
return body[0]
def visit_Name(self, node):
return Var(node.id)
def visit_Num(self, node):
if isinstance(node.n, float):
return LitFloat(node.n)
else:
return LitInt(node.n)
def visit_Bool(self, node):
return LitBool(node.n)
def visit_Call(self, node):
name = self.visit(node.func)
args = map(self.visit, node.args)
keywords = map(self.visit, node.keywords)
return App(name, args)
def visit_BinOp(self, node):
op_str = node.op.__class__
a = self.visit(node.left)
b = self.visit(node.right)
opname = primops[op_str]
return Prim(opname, [a, b])
def visit_Assign(self, node):
targets = node.targets
assert len(node.targets) == 1
var = node.targets[0].id
val = self.visit(node.value)
return Assign(var, val)
def visit_FunctionDef(self, node):
stmts = list(node.body)
stmts = map(self.visit, stmts)
args = map(self.visit, node.args.args)
res = Fun(node.name, args, stmts)
return res
def visit_Pass(self, node):
return Noop()
def visit_Lambda(self, node):
args = self.visit(node.args)
body = self.visit(node.body)
def visit_Return(self, node):
val = self.visit(node.value)
return Return(val)
def visit_Attribute(self, node):
if node.attr == "shape":
val = self.visit(node.value)
return Prim("shape#", [val])
else:
raise NotImplementedError
def visit_Subscript(self, node):
if isinstance(node.ctx, ast.Load):
if node.slice:
val = self.visit(node.value)
ix = self.visit(node.slice.value)
return Index(val, ix)
elif isinstance(node.ctx, ast.Store):
raise NotImplementedError
def visit_For(self, node):
target = self.visit(node.target)
stmts = map(self.visit, node.body)
if node.iter.func.id in {"xrange", "range"}:
args = map(self.visit, node.iter.args)
else:
raise Exception("Loop must be over range")
if len(args) == 1: # xrange(n)
return Loop(target, LitInt(0, type=int32), args[0], stmts)
elif len(args) == 2: # xrange(n,m)
return Loop(target, args[0], args[1], stmts)
def visit_AugAssign(self, node):
if isinstance(node.op, ast.Add):
ref = node.target.id
value = self.visit(node.value)
return Assign(ref, Prim("add#", [Var(ref), value]))
if isinstance(node.op, ast.Mul):
ref = node.target.id
value = self.visit(node.value)
return Assign(ref, Prim("mult#", [Var(ref), value]))
else:
raise NotImplementedError
def generic_visit(self, node):
raise NotImplementedError
So if we define a very simple function like:
def add(a,b):
return a + b
There are several builtin "primops" which are simply functions which have a direct mapping to some function lower in the pipeline.
add#: Generic addition (integral, floating point)mult#: Generic multiplication (integral, floating point)shape#: Shape extraction for NumPy ndarrays.
primops = {ast.Add: "add#", ast.Mult: "mult#"}
And run our transformer over it with:
transformer = PythonVisitor()
core = transformer(add)
print(pformat_ast(core))
For a more complex function consider:
def count(n):
a = 0
for i in range(0, n):
a += i
return a
transformer = PythonVisitor()
core = transformer(count)
print(pformat_ast(core))
Type Inference
For type inference we wish to take our untyped AST and overlay types deduced from two sources
- Types intrinsic to the operations in use
- User input types
To do this we will use a very traditional method of constraint based unification for type reconstruction. We will walk our AST generating a constraint set of equality relations between types (written as a ~ b), which will give rise to a large constraint problem we will solve when given a set of input types for arguments. Whenever we don't know the type of an expression we will place a fresh free type variable in it's place and solve for it when given more information.
There are four possible outcomes:
- The types are correctly determined.
- The types are underdetermined.
- The types is polymorphic.
- The types are inconsistent.
The case where the function is polymorphic implies that there are free type variables remaining in the toplevel type. For instance we might have a type like:
[Array a, Array a] -> a
Which just means that the logic is independent of the type of the element of the arrays, and can operate polymorphicly over any element type. This is good for code reuse and implies we get a whole family of functions supposing that our compiler knows how to lower a.
The types are underdetermined. Implies that the constraints induced by usage are too lax to fully determine every subexpression. In this case an explicit annotation is needed.
The type inconsistent. This will happen where there is no solution that would satisfy the given constraints. For example trying to a call function with signature:
[a,a] -> a
Over the types [Int64, Double] has no solution since there can be no solution where Int64 ~ Double.
def naming():
k = 0
while True:
for a in string.ascii_lowercase:
yield ("'"+a+str(k)) if (k > 0) else (a)
k = k+1
class TypeInfer(object):
def __init__(self):
self.constraints = []
self.env = {}
self.names = naming()
def fresh(self):
return TVar('$' + next(self.names)) # New meta type variable.
def visit(self, node):
name = "visit_%s" % type(node).__name__
if hasattr(self, name):
return getattr(self, name)(node)
else:
return self.generic_visit(node)
def visit_Fun(self, node):
arity = len(node.args)
self.argtys = [self.fresh() for v in node.args]
self.retty = TVar("$retty")
for (arg, ty) in zip(node.args, self.argtys):
arg.type = ty
self.env[arg.id] = ty
map(self.visit, node.body)
return TFun(self.argtys, self.retty)
def visit_Noop(self, node):
return None
def visit_LitInt(self, node):
tv = self.fresh()
node.type = tv
return tv
def visit_LitFloat(self, node):
tv = self.fresh()
node.type = tv
return tv
def visit_Assign(self, node):
ty = self.visit(node.val)
if node.ref in self.env:
# Subsequent uses of a variable must have the same type.
self.constraints += [(ty, self.env[node.ref])]
self.env[node.ref] = ty
node.type = ty
return None
def visit_Index(self, node):
tv = self.fresh()
ty = self.visit(node.val)
ixty = self.visit(node.ix)
self.constraints += [(ty, array(tv)), (ixty, int32)]
return tv
def visit_Prim(self, node):
if node.fn == "shape#":
return array(int32)
elif node.fn == "mult#":
tya = self.visit(node.args[0])
tyb = self.visit(node.args[1])
self.constraints += [(tya, tyb)]
return tyb
elif node.fn == "add#":
tya = self.visit(node.args[0])
tyb = self.visit(node.args[1])
self.constraints += [(tya, tyb)]
return tyb
else:
raise NotImplementedError
def visit_Var(self, node):
ty = self.env[node.id]
node.type = ty
return ty
def visit_Return(self, node):
ty = self.visit(node.val)
self.constraints += [(ty, self.retty)]
def visit_Loop(self, node):
self.env[node.var.id] = int32
varty = self.visit(node.var)
begin = self.visit(node.begin)
end = self.visit(node.end)
self.constraints += [(varty, int32), (
begin, int64), (end, int32)]
map(self.visit, node.body)
def generic_visit(self, node):
raise NotImplementedError
When the traversal is finished we'll have a set of constraints to solve:
def addup(n):
x = 1
for i in range(n):
n += 1 + x
return n
transformer = PythonVisitor()
core = transformer(addup)
infer = TypeInfer()
sig = infer.visit(core)
print('Signature:%s \n' % sig)
print('Constraints:')
for (a,b) in infer.constraints:
print(a, '~', b)
So now we're left with a little riddle to reduce the number variables in the expression by equating like terms. We also notice that the inference has annotated our AST with explicit type terms for all the free variables.
print(pformat_ast(core))
So now we'll solve the system of equations using the very traditional unification solver via Robinson's algorithm. The solver will recursively build up the most general unifier (mgu) which is a substitution which when applied to the term yields the minimal singleton solution set.
def empty():
return {}
def apply(s, t):
if isinstance(t, TCon):
return t
elif isinstance(t, TApp):
return TApp(apply(s, t.a), apply(s, t.b))
elif isinstance(t, TFun):
argtys = [apply(s, a) for a in t.argtys]
retty = apply(s, t.retty)
return TFun(argtys, retty)
elif isinstance(t, TVar):
return s.get(t.s, t)
def applyList(s, xs):
return [(apply(s, x), apply(s, y)) for (x, y) in xs]
def unify(x, y):
if isinstance(x, TApp) and isinstance(y, TApp):
s1 = unify(x.a, y.a)
s2 = unify(apply(s1, x.b), apply(s1, y.b))
return compose(s2, s1)
elif isinstance(x, TCon) and isinstance(y, TCon) and (x == y):
return empty()
elif isinstance(x, TFun) and isinstance(y, TFun):
if len(x.argtys) != len(y.argtys):
return Exception("Wrong number of arguments")
s1 = solve(zip(x.argtys, y.argtys))
s2 = unify(apply(s1, x.retty), apply(s1, y.retty))
return compose(s2, s1)
elif isinstance(x, TVar):
return bind(x.s, y)
elif isinstance(y, TVar):
return bind(y.s, x)
else:
raise InferError(x, y)
def solve(xs):
mgu = empty()
cs = deque(xs)
while len(cs):
(a, b) = cs.pop()
s = unify(a, b)
mgu = compose(s, mgu)
cs = deque(applyList(s, cs))
return mgu
def bind(n, x):
if x == n:
return empty()
elif occurs_check(n, x):
raise InfiniteType(n, x)
else:
return dict([(n, x)])
def occurs_check(n, x):
return n in ftv(x)
def union(s1, s2):
nenv = s1.copy()
nenv.update(s2)
return nenv
def compose(s1, s2):
s3 = dict((t, apply(s1, u)) for t, u in s2.items())
return union(s1, s3)
class UnderDeteremined(Exception):
def __str__(self):
return "The types in the function are not fully determined by the \
input types. Add annotations."
class InferError(Exception):
def __init__(self, ty1, ty2):
self.ty1 = ty1
self.ty2 = ty2
def __str__(self):
return '\n'.join([
"Type mismatch: ",
"Given: ", "\t" + str(self.ty1),
"Expected: ", "\t" + str(self.ty2)
])
def dot2(a, b):
c = 0
n = a.shape[0]
for i in range(n):
c += a[i]*b[i]
return c
def test_infer(fn):
transformer = PythonVisitor()
ast = transformer(fn)
infer = TypeInfer()
ty = infer.visit(ast)
mgu = solve(infer.constraints)
infer_ty = apply(mgu, ty)
print('Unifier: ')
for (a,b) in mgu.iteritems():
print(a + ' ~ ' + str(b))
print('Solution: ', infer_ty)
test_infer(dot2)
So in this case we have solution
[Array $c, Array $c] -> $c
indicating that our dot product function is polymorphic in both of it's arguments and return type. It works for any array.
def addup(n):
x = 1
for i in range(n):
n += i + x
return n
test_infer(addup)
Where as for the addup function our inferred type is simply entirely determiend by the type of iteration variable, which we for range we defined to default to Int32 which determines both the type of the input and the type of the output and the intermediate type of x.
Consider now a case where the system is underdetermined. If we ignore one of the arguments then our system doesn't have any constraints to solve for and it's simply left as a free variable.
def const(a,b):
return a
test_infer(addup)
LLVM Code Generator
Now we set up another type system, the LLVM type system which map directly onto machine types for our platform.
The only nonobvious thing going on here is that our NumPy arrays will be passed around as a structure object that holds metadata from the originally NumPy ndarray. The data pointer is simply the pointer to data buffer that NumPy allocated for it's values. In C we would write:
struct ndarray_double {
data *double;
dims int;
shape *int;
}pointer = Type.pointer
int_type = Type.int()
float_type = Type.float()
double_type = Type.double()
bool_type = Type.int(1)
void_type = Type.void()
void_ptr = pointer(Type.int(8))
def array_type(elt_type):
return Type.struct([
pointer(elt_type), # data
int_type, # dimensions
pointer(int_type), # shape
], name='ndarray_' + str(elt_type))
int32_array = pointer(array_type(int_type))
int64_array = pointer(array_type(Type.int(64)))
double_array = pointer(array_type(double_type))
lltypes_map = {
int32 : int_type,
int64 : int_type,
float32 : float_type,
double64 : double_type,
array_int32 : int32_array,
array_int64 : int64_array,
array_double64 : double_array
}
def to_lltype(ptype):
return lltypes_map[ptype]
def determined(ty):
return len(ftv(ty)) == 0
Now the meat of the whole system is the LLVMEmitter class, which is a few hundred lines. Effectively we create a LLVM builder upon initialization and then traverse through our core AST. The important functions are:
- start_function: Creates the initial basic block structure. Shifts the instruction "cursor" to the first block and then starts running through each of the statements in the body of the function to add logic.
- add_block: Creates a new basic block.
- set_block: Sets the active basic block that we are adding instructions to.
- specialize: Extracts the type of the subexpression from the AST and maps our custom type into a LLVM type.
The metadata for all array arguments is automatically stack allocated in the entry block so that subsequent accesses just have to look at the constant load'd values. These are stored in the arrays dictionary which holds all NumPy array arguments and their metadata.
The special retval reference holds the return value that the function will yield when the exit_block. in Whenever a name binder occurs we will look the AST, which is likely a type variable given to us from the inference engine. Since our type signature is fully determiend at this point we then need only look in the spec_types dictionary for what concrete type this subexpression has.
class LLVMEmitter(object):
def __init__(self, spec_types, retty, argtys):
self.function = None # LLVM Function
self.builder = None # LLVM Builder
self.locals = {} # Local variables
self.arrays = defaultdict(dict) # Array metadata
self.exit_block = None # Exit block
self.spec_types = spec_types # Type specialization
self.retty = retty # Return type
self.argtys = argtys # Argument types
def start_function(self, name, module, rettype, argtypes):
func_type = lc.Type.function(rettype, argtypes, False)
function = lc.Function.new(module, func_type, name)
entry_block = function.append_basic_block("entry")
builder = lc.Builder.new(entry_block)
self.exit_block = function.append_basic_block("exit")
self.function = function
self.builder = builder
def end_function(self):
self.builder.position_at_end(self.exit_block)
if 'retval' in self.locals:
retval = self.builder.load(self.locals['retval'])
self.builder.ret(retval)
else:
self.builder.ret_void()
def add_block(self, name):
return self.function.append_basic_block(name)
def set_block(self, block):
self.block = block
self.builder.position_at_end(block)
def cbranch(self, cond, true_block, false_block):
self.builder.cbranch(cond, true_block, false_block)
def branch(self, next_block):
self.builder.branch(next_block)
def specialize(self, val):
if isinstance(val.type, TVar):
return to_lltype(self.spec_types[val.type.s])
else:
return val.type
def const(self, val):
if isinstance(val, (int, long)):
return Constant.int(int_type, val)
elif isinstance(val, float):
return Constant.real(double_type, val)
elif isinstance(val, bool):
return Constant.int(bool_type, int(val))
elif isinstance(val, str):
return Constant.stringz(val)
else:
raise NotImplementedError
def visit_LitInt(self, node):
ty = self.specialize(node)
if ty is double_type:
return Constant.real(double_type, node.n)
elif ty == int_type:
return Constant.int(int_type, node.n)
def visit_LitFloat(self, node):
ty = self.specialize(node)
if ty is double_type:
return Constant.real(double_type, node.n)
elif ty == int_type:
return Constant.int(int_type, node.n)
def visit_Noop(self, node):
pass
def visit_Fun(self, node):
rettype = to_lltype(self.retty)
argtypes = map(to_lltype, self.argtys)
# Create a unique specialized name
func_name = mangler(node.fname, self.argtys)
self.start_function(func_name, module, rettype, argtypes)
for (ar, llarg, argty) in zip(node.args, self.function.args, self.argtys):
name = ar.id
llarg.name = name
if is_array(argty):
zero = self.const(0)
one = self.const(1)
two = self.const(2)
data = self.builder.gep(llarg, [
zero, zero], name=(name + '_data'))
dims = self.builder.gep(llarg, [
zero, one], name=(name + '_dims'))
shape = self.builder.gep(llarg, [
zero, two], name=(name + '_strides'))
self.arrays[name]['data'] = self.builder.load(data)
self.arrays[name]['dims'] = self.builder.load(dims)
self.arrays[name]['shape'] = self.builder.load(shape)
self.locals[name] = llarg
else:
argref = self.builder.alloca(to_lltype(argty))
self.builder.store(llarg, argref)
self.locals[name] = argref
# Setup the register for return type.
if rettype is not void_type:
self.locals['retval'] = self.builder.alloca(rettype, "retval")
map(self.visit, node.body)
self.end_function()
def visit_Index(self, node):
if isinstance(node.val, Var) and node.val.id in self.arrays:
val = self.visit(node.val)
ix = self.visit(node.ix)
dataptr = self.arrays[node.val.id]['data']
ret = self.builder.gep(dataptr, [ix])
return self.builder.load(ret)
else:
val = self.visit(node.val)
ix = self.visit(node.ix)
ret = self.builder.gep(val, [ix])
return self.builder.load(ret)
def visit_Var(self, node):
return self.builder.load(self.locals[node.id])
def visit_Return(self, node):
val = self.visit(node.val)
if val.type != void_type:
self.builder.store(val, self.locals['retval'])
self.builder.branch(self.exit_block)
def visit_Loop(self, node):
init_block = self.function.append_basic_block('for.init')
test_block = self.function.append_basic_block('for.cond')
body_block = self.function.append_basic_block('for.body')
end_block = self.function.append_basic_block("for.end")
self.branch(init_block)
self.set_block(init_block)
start = self.visit(node.begin)
stop = self.visit(node.end)
step = 1
# Setup the increment variable
varname = node.var.id
inc = self.builder.alloca(int_type, varname)
self.builder.store(start, inc)
self.locals[varname] = inc
# Setup the loop condition
self.branch(test_block)
self.set_block(test_block)
cond = self.builder.icmp(lc.ICMP_SLT, self.builder.load(inc), stop)
self.builder.cbranch(cond, body_block, end_block)
# Generate the loop body
self.set_block(body_block)
map(self.visit, node.body)
# Increment the counter
succ = self.builder.add(self.const(step), self.builder.load(inc))
self.builder.store(succ, inc)
# Exit the loop
self.builder.branch(test_block)
self.set_block(end_block)
def visit_Prim(self, node):
if node.fn == "shape#":
ref = node.args[0]
shape = self.arrays[ref.id]['shape']
return shape
elif node.fn == "mult#":
a = self.visit(node.args[0])
b = self.visit(node.args[1])
if a.type == double_type:
return self.builder.fmul(a, b)
else:
return self.builder.mul(a, b)
elif node.fn == "add#":
a = self.visit(node.args[0])
b = self.visit(node.args[1])
if a.type == double_type:
return self.builder.fadd(a, b)
else:
return self.builder.add(a, b)
else:
raise NotImplementedError
def visit_Assign(self, node):
# Subsequent assignment
if node.ref in self.locals:
name = node.ref
var = self.locals[name]
val = self.visit(node.val)
self.builder.store(val, var)
self.locals[name] = var
return var
# First assignment
else:
name = node.ref
val = self.visit(node.val)
ty = self.specialize(node)
var = self.builder.alloca(ty, name)
self.builder.store(val, var)
self.locals[name] = var
return var
def visit(self, node):
name = "visit_%s" % type(node).__name__
if hasattr(self, name):
return getattr(self, name)(node)
else:
return self.generic_visit(node)
def generic_visit(self, node):
raise NotImplementedError
This class may look big, but a lot of it is actually just the same logic over and over. The only non-trivial bit is the loop which is really just simple four basic blocks that jump between each other based on a loop condition just like the simple count example from the first section. If we graph the control flow for our loop constuctor it looks like:
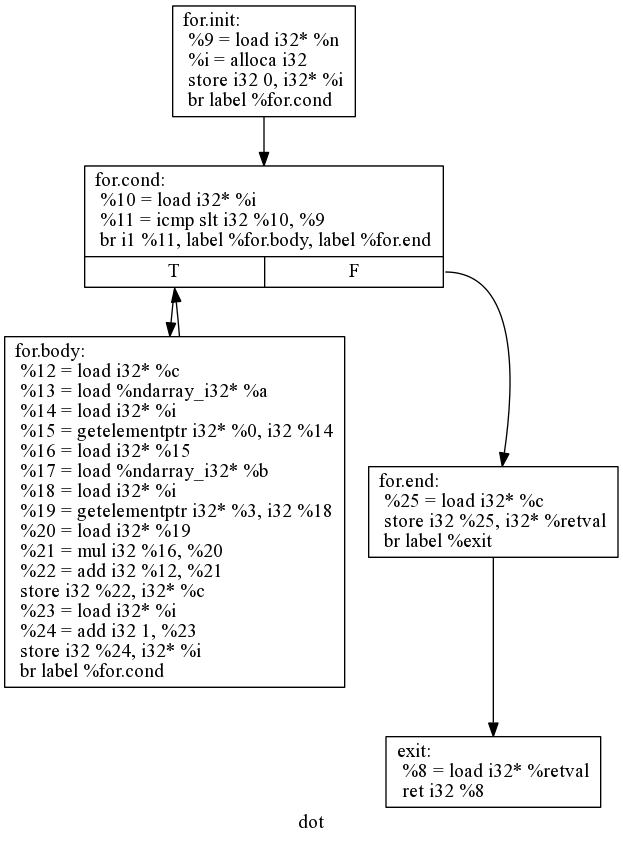
So as not to duplicate work we'll create a unique mangled name for each function that is defined in terms of the hash of it's argument types. Every autojit'd function can map onto several mangled LLVM functions in the current module. This guarantees that names don't clash. It also gives us a way to cache on the argument types so that functions will not get recompiled and reJIT'd if the arguments given are identical to a function that has previously run.
def mangler(fname, sig):
return fname + str(hash(tuple(sig)))
Now to actually invoke our function we'll use the ExecutionEngine as before, but we'd like to able to seamlessly go back and forth between Python/NumPy types without having to manually convert. To do this we'll use the ctypes/libffi wrapper to automatically lower the Python types into their C equivelants. Hat tip to Dave Beazley for documenting this technique in the Python Cookbook.
_nptypemap = {
'i': ctypes.c_int,
'f': ctypes.c_float,
'd': ctypes.c_double,
}
def wrap_module(sig, llfunc):
pfunc = wrap_function(llfunc, engine)
dispatch = dispatcher(pfunc)
return dispatch
def wrap_function(func, engine):
args = func.type.pointee.args
ret_type = func.type.pointee.return_type
ret_ctype = wrap_type(ret_type)
args_ctypes = map(wrap_type, args)
functype = ctypes.CFUNCTYPE(ret_ctype, *args_ctypes)
fptr = engine.get_pointer_to_function(func)
cfunc = functype(fptr)
cfunc.__name__ = func.name
return cfunc
def wrap_type(llvm_type):
kind = llvm_type.kind
if kind == lc.TYPE_INTEGER:
ctype = getattr(ctypes, "c_int"+str(llvm_type.width))
elif kind == lc.TYPE_DOUBLE:
ctype = ctypes.c_double
elif kind == lc.TYPE_FLOAT:
ctype = ctypes.c_float
elif kind == lc.TYPE_VOID:
ctype = None
elif kind == lc.TYPE_POINTER:
pointee = llvm_type.pointee
p_kind = pointee.kind
if p_kind == lc.TYPE_INTEGER:
width = pointee.width
if width == 8:
ctype = ctypes.c_char_p
else:
ctype = ctypes.POINTER(wrap_type(pointee))
elif p_kind == lc.TYPE_VOID:
ctype = ctypes.c_void_p
else:
ctype = ctypes.POINTER(wrap_type(pointee))
elif kind == lc.TYPE_STRUCT:
struct_name = llvm_type.name.split('.')[-1]
struct_name = struct_name.encode('ascii')
struct_type = None
if struct_type and issubclass(struct_type, ctypes.Structure):
return struct_type
if hasattr(struct_type, '_fields_'):
names = struct_type._fields_
else:
names = ["field"+str(n) for n in range(llvm_type.element_count)]
ctype = type(ctypes.Structure)(struct_name, (ctypes.Structure,),
{'__module__': "numpile"})
fields = [(name, wrap_type(elem))
for name, elem in zip(names, llvm_type.elements)]
setattr(ctype, '_fields_', fields)
else:
raise Exception("Unknown LLVM type %s" % kind)
return ctype
def wrap_ndarray(na):
# For NumPy arrays grab the underlying data pointer. Doesn't copy.
ctype = _nptypemap[na.dtype.char]
_shape = list(na.shape)
data = na.ctypes.data_as(ctypes.POINTER(ctype))
dims = len(na.strides)
shape = (ctypes.c_int*dims)(*_shape)
return (data, dims, shape)
def wrap_arg(arg, val):
if isinstance(val, np.ndarray):
ndarray = arg._type_
data, dims, shape = wrap_ndarray(val)
return ndarray(data, dims, shape)
else:
return val
def dispatcher(fn):
def _call_closure(*args):
cargs = list(fn._argtypes_)
pargs = list(args)
rargs = map(wrap_arg, cargs, pargs)
return fn(*rargs)
_call_closure.__name__ = fn.__name__
return _call_closure
Toplevel
The toplevel will consists of the autojit decorator which maps the function through translator, does type inference, and the creates a closure which when called will automatically specialize the function to the given argument types and compile a new version if needed. We will cache based on the arguments ( which entirely define the function ) and whenever a similar typed argument set is passed we just lookup the preJIT'd function and invoke it with no overhead.
module = lc.Module.new('numpile.module')
engine = None
function_cache = {}
tm = le.TargetMachine.new(features='', cm=le.CM_JITDEFAULT)
eb = le.EngineBuilder.new(module)
engine = eb.create(tm)
def autojit(fn):
transformer = PythonVisitor()
ast = transformer(fn)
(ty, mgu) = typeinfer(ast)
return specialize(ast, ty, mgu)
def typeinfer(ast):
infer = TypeInfer()
ty = infer.visit(ast)
mgu = solve(infer.constraints)
infer_ty = apply(mgu, ty)
return (infer_ty, mgu)
def codegen(ast, specializer, retty, argtys):
cgen = LLVMEmitter(specializer, retty, argtys)
mod = cgen.visit(ast)
cgen.function.verify()
print(cgen.function)
print(module.to_native_assembly())
return cgen.function
And finally the argument specializer logic.
def arg_pytype(arg):
if isinstance(arg, np.ndarray):
if arg.dtype == np.dtype('int32'):
return array(int32)
elif arg.dtype == np.dtype('int64'):
return array(int64)
elif arg.dtype == np.dtype('double'):
return array(double64)
elif arg.dtype == np.dtype('float'):
return array(float32)
elif isinstance(arg, int) & (arg < sys.maxint):
return int64
elif isinstance(arg, float):
return double64
else:
raise Exception("Type not supported: %s" % type(arg))
def specialize(ast, infer_ty, mgu):
def _wrapper(*args):
types = map(arg_pytype, list(args))
spec_ty = TFun(argtys=types, retty=TVar("$retty"))
unifier = unify(infer_ty, spec_ty)
specializer = compose(unifier, mgu)
retty = apply(specializer, TVar("$retty"))
argtys = [apply(specializer, ty) for ty in types]
print('Specialized Function:', TFun(argtys, retty))
if determined(retty) and all(map(determined, argtys)):
key = mangler(ast.fname, argtys)
# Don't recompile after we've specialized.
if key in function_cache:
return function_cache[key](*args)
else:
llfunc = codegen(ast, specializer, retty, argtys)
pyfunc = wrap_module(argtys, llfunc)
function_cache[key] = pyfunc
return pyfunc(*args)
else:
raise UnderDeteremined()
return _wrapper
OK, so basically we're done, we built the thing top to bottom so let's try it out. Keep in mind that this IR is without optimizations so it will do several naive things that the optimizer will clean up later.
@autojit
def add(a, b):
return a+b
a = 3.1415926
b = 2.7182818
print('Result:', add(a,b))
And how about for our dot product function.
@autojit
def dot(a, b):
c = 0
n = a.shape[0]
for i in range(n):
c += a[i]*b[i]
return c
We'll get a lot of debug output for this one.
a = np.array(range(1000,2000), dtype='int32')
b = np.array(range(3000,4000), dtype='int32')
print('Result:', dot(a,b))
Ok, now let's turn the optimizer on and have it have it automatically transform not only our naive code, but replace most of our inner loop with more optimial instructions.
def codegen(ast, specializer, retty, argtys):
cgen = LLVMEmitter(specializer, retty, argtys)
mod = cgen.visit(ast)
cgen.function.verify()
tm = le.TargetMachine.new(opt=3, cm=le.CM_JITDEFAULT, features='')
pms = lp.build_pass_managers(tm=tm,
fpm=False,
mod=module,
opt=3,
vectorize=False,
loop_vectorize=True)
pms.pm.run(module)
print(cgen.function)
return cgen.function
@autojit
def dot_vectorize(a, b):
c = 0
n = a.shape[0]
for i in range(n):
c += a[i]*b[i]
return c
With the optimizer in full force LLVM has replaced most of our loop with SIMD and vector instructions and partially unrolled the loops for the dot product, as well as doing the usual dead code elimination, control flow simplification.
a = np.array(range(1000,2000), dtype='int32')
b = np.array(range(3000,4000), dtype='int32')
print('Result:', dot_vectorize(a,b))
Further Work
While this example is kind of simplified (we only have addition and multiplication after all!), in principle all the ideas and machinary you would need to build out a full system are basically sketched here. Some further fruitful areas:
- Translate all of the Python AST
- Use subpy to do feature detection before lowering the function into LLVM. Gives better error reporting when an invalid high-level feature is used instead of failing somewhere in the middle of the compiler pipeline.
- Use the lineno and column information on the Python AST to add better error handling.
- Add more types and explicit casts or bidirectional type inference.
- For untranslatable calls, use the Object Layer in the C-API to reach back into the interpreter.
- Map a subset of numpy calls into LLVM.
- Use the LLVM nvptx backend for targeting Python logic into Nvidia CUDA kernels.
- Use pthreads inside of LLVM to logic write multicore programs withou the usual GIL constraints.
- Use MPI or ZeroMQ's zero-copy array transfer efficiently push distributed numerical kernels across multiple machine.
- Add composite numerical types, complex numbers, quaternions.
Resources
I've written about LLVM quite a bit lately.